
Measuring LLM Performance
This article explains why measuring large language models (LLMs) is crucial for ensuring decision-making accuracy, ethical compliance, operational efficiency, and adaptability to business needs.


The rapid development of large language models (LLMs) such as GPT-4, BERT, and others has led to a significant transformation in how businesses and organizations use AI to solve complex problems. However, despite their impressive capabilities, it is essential to understand how these models perform across various dimensions. Measuring AI models is not just about determining their technical accuracy; it involves evaluating how well they meet specific business goals, align with ethical standards, and remain flexible enough to adapt to evolving real-world conditions. The ability to measure and optimize these models is crucial for businesses that aim to deploy AI in a sustainable and responsible manner.
One of the core challenges in AI deployment is ensuring that the models are aligned with business objectives. AI models are only as useful as the results they produce in real-world applications. Therefore, it is critical to assess them across a wide range of performance metrics, including operational efficiency, scalability, and content quality. These metrics help organizations tailor AI systems to their specific needs, ensuring they can operate effectively under various business contexts and across different industries. Understanding these dimensions allows businesses to maximize the value of their AI investments.
Another major issue that AI organizations face is building trust and ensuring accountability, particularly in high-stakes environments like healthcare, law, and finance. Ethical and security metrics help companies ensure their AI systems are fair, unbiased, and secure. These evaluations prevent models from making biased decisions or being manipulated by adversarial inputs. Trustworthy AI systems can significantly enhance user satisfaction and business outcomes while reducing the risk of reputational damage or regulatory penalties.
Finally, measuring large language models is about ensuring long-term adaptability and business viability. AI models must not only perform well today but also adapt to future market changes, language trends, and shifting customer expectations. As industries evolve and new technologies emerge, businesses need AI systems that can scale, update, and remain relevant without constant retraining. Metrics that evaluate adaptability and scalability provide a clear path for businesses to implement AI solutions that drive continuous growth and innovation.

Why LLM Metrics Matter
1. Improved Decision-Making
What It Measures: Metrics such as task-specific performance, knowledge retrieval, and reasoning efficiency help evaluate how well an LLM performs in decision-making scenarios. These metrics allow organizations to assess whether the model is accurate and effective at generating relevant insights based on complex data or specific tasks.
Significance: Measuring LLM performance in decision-making processes enables companies to tailor AI systems to fit their operational needs more precisely. For example, in finance or healthcare, where critical decisions depend on accurate and logical insights, it is vital to know how well the AI performs under various task demands. Organizations can make more informed decisions about AI deployment, aligning models with business goals to optimize overall efficiency.
2. Operational Efficiency
What It Measures: Metrics like inference latency, deployment resilience, and stability across versions assess how efficiently the AI operates in live environments, particularly focusing on its speed, uptime, and ability to handle fluctuating workloads.
Significance: Ensuring that AI systems perform efficiently in real-time, without delays or crashes, is critical in customer-facing applications like e-commerce, customer service, or banking. Measuring these aspects ensures that the AI maintains seamless interactions with minimal downtime, boosting user satisfaction and helping the business scale its operations without compromising performance.
3. Trust and Accountability
What It Measures: Metrics such as bias detection, ethical compliance, and toxicity avoidance evaluate whether the model adheres to ethical guidelines, remains free from harmful biases, and avoids generating offensive or misleading content.
Significance: In sensitive fields such as healthcare, law, or hiring, maintaining trust is essential for both end-users and regulators. These metrics ensure that the AI operates transparently and fairly, reducing the risk of bias or unethical behavior. This is particularly important as organizations aim to comply with legal regulations and maintain a positive public image, ultimately safeguarding their reputation.
4. Financial ROI
What It Measures: Metrics like business relevance score, economic impact simulation, and cost-efficiency ratio assess the financial benefits generated by deploying AI systems, such as cost savings, revenue growth, and productivity improvements.
Significance: Demonstrating a strong financial return on investment (ROI) is crucial for stakeholders considering AI deployment. These metrics quantify the tangible benefits of AI, helping companies justify AI investments by showing the financial gains in productivity, operational savings, or revenue increases. This data is especially useful for executives and decision-makers who need to evaluate the long-term value of AI projects.
5. Scalability and Adaptability
What It Measures: Metrics like dynamic language adaptation, cross-language transferability, and prompt engineering robustness evaluate the model’s ability to adapt to new languages, evolving prompts, or changing business requirements without retraining.
Significance: Adaptability is crucial in dynamic environments where user expectations, languages, and industry trends constantly change. For instance, a global e-commerce business that interacts with customers in multiple languages needs an AI that can adapt to different linguistic and cultural contexts. Measuring adaptability reduces the need for frequent retraining, saving time and resources while maintaining AI relevance across various domains.
6. Content Quality and Coherence
What It Measures: Metrics like fluency, coherence, and lexical diversity assess the quality of text generated by the AI, focusing on readability, grammatical accuracy, and logical flow between sentences and paragraphs.
Significance: High-quality content is a must in industries such as marketing, journalism, and creative writing, where the output needs to be professional, engaging, and free of errors. Metrics that evaluate content fluency and coherence ensure that AI-generated text meets the standards of human-like writing, reducing the need for manual editing and enhancing the overall professionalism of automated outputs.
7. Mitigating Risks in High-Stakes Applications
Why It Matters: In industries like healthcare, legal services, and finance, incorrect or misleading AI outputs can have serious consequences, including legal liability or harm to individuals. Measuring AI performance in terms of factual accuracy, ethical compliance, and bias detection ensures that these systems are safe to use in critical applications.
Example: An LLM providing incorrect legal advice could lead to adverse court decisions. Similarly, in healthcare, erroneous medical recommendations could harm patients. By rigorously measuring AI’s factual accuracy and bias, businesses can mitigate these risks.
8. Personalization at Scale
Why It Matters: Effective personalization of content is critical in modern business, from e-commerce to marketing. Measuring LLMs on their ability to personalize outputs based on individual user behavior and preferences helps businesses create more engaging and tailored experiences for large, diverse user bases.
Example: An LLM powering a recommendation engine for an e-commerce platform must continuously adapt its suggestions based on user preferences. Metrics such as user personalization precision ensure that the model is delivering relevant, individualized recommendations without retraining for each user interaction.
9. Enhancing User Experience
Why It Matters: Measuring LLMs in terms of human interaction metrics, such as dialogue quality and sentiment alignment, ensures that the AI creates positive user experiences. For customer service applications, where users expect empathetic, relevant, and coherent interactions, this can greatly improve customer satisfaction and loyalty.
Example: If an LLM used in a customer support chatbot does not maintain coherent conversations or responds with irrelevant information, it can frustrate users. Measuring dialogue quality ensures that the AI provides meaningful and fluid conversations, improving overall user satisfaction.
10. Supporting Ethical AI Development
Why It Matters: As AI becomes more embedded in everyday life, ensuring its outputs are ethical is critical. Measuring bias, fairness, and adherence to ethical guidelines prevents the propagation of harmful stereotypes or unfair decision-making processes in AI systems. Ethical AI leads to trustworthiness, which is essential for user adoption and public acceptance.
Example: In hiring platforms or loan approval systems, bias against certain demographics can lead to unfair treatment. Metrics that measure bias detection and fairness ensure that the model's decisions are equitable, thus preventing discrimination and ensuring compliance with legal standards.
11. Adapting to Real-Time Changes in Market and Language Trends
Why It Matters: Businesses need AI systems that can adapt quickly to changes in language and market trends without frequent retraining. By measuring adaptability, such as dynamic language adaptation and prompt engineering robustness, companies can ensure their AI models remain effective in real-time without significant operational overhead.
Example: In social media management or content marketing, the language and topics of interest evolve rapidly. LLMs that can adapt to these trends in real-time ensure businesses remain relevant and responsive to current conversations.
12. Enabling Data-Driven AI Improvement
Why It Matters: Continuous measurement of AI performance provides the data needed for ongoing improvement. Understanding how an LLM performs across different tasks, contexts, and environments allows developers to identify areas for optimization, whether improving accuracy, reducing biases, or enhancing speed.
Example: If a business tracks the model’s inference latency or error rates over time, they can identify patterns of degradation or inefficiency, enabling targeted retraining or refinement. This constant feedback loop ensures that AI performance remains optimized, increasing its long-term value to the organization.
What Can Be Measured
Task-Specific Performance
Metrics: Accuracy, Precision, Recall, F1 Score.
What It Measures: Task-specific performance metrics evaluate how well an AI model performs narrowly defined tasks such as answering legal questions or generating summaries.
Significance: These metrics ensure that AI models meet the precise needs of specialized applications, enabling them to be adapted for highly specific tasks like legal document review or financial forecasting. Without task-specific evaluation, AI models may perform well in general but fail to meet the nuanced requirements of specific industries.
Human Interaction & Communication
Metrics: Compassion Response Score, Interactive Dialogue Quality, Sentiment Alignment.
What It Measures: These metrics assess how naturally AI interacts with users, ensuring that responses are fluent, contextually relevant, and emotionally aligned with the user’s sentiment.
Significance: In customer service, healthcare, and virtual assistants, human-like communication is crucial. Models that produce empathetic, coherent, and context-aware responses foster better user engagement, reducing frustration and improving overall satisfaction.
Security, Ethical, and Compliance
Metrics: Bias Detection Index, Ethical Compliance Rating, Adversarial Input Handling.
What It Measures: These metrics assess the model's adherence to ethical guidelines, its robustness against adversarial attacks, and its ability to avoid biased or toxic outputs.
Significance: Ensuring AI models are free from bias and resistant to malicious manipulation is critical in regulated industries like finance and healthcare. Robust ethical and security evaluations help organizations avoid legal and reputational risks, fostering trust in AI systems.
Operational Performance
Metrics: Inference Latency, Real-World Deployment Resilience, Stability Across Versions.
What It Measures: These metrics evaluate how well an AI model performs in live, real-world environments, focusing on response times, consistency, and scalability.
Significance: In high-demand environments like e-commerce, quick response times and system stability are essential to maintaining business continuity and customer satisfaction. Measuring operational performance ensures the AI can handle fluctuations in user traffic and maintain reliability during updates.
Business & Economic Impact
Metrics: Economic Impact Simulation, Business Relevance Score, Cost-Efficiency Ratio.
What It Measures: These metrics assess the financial benefits of deploying an AI model, such as productivity gains, cost savings, and revenue growth.
Significance: For businesses, the ROI of AI systems is a critical consideration. Measuring the economic impact ensures that AI investments are justified, helping organizations make informed decisions about scaling AI deployment.
Adaptability & Flexibility
Metrics: Dynamic Language Adaptation, Prompt Engineering Robustness, Cross-Language Transferability.
What It Measures: These metrics evaluate the model’s ability to adapt to changes in language trends, input variations, and different contexts.
Significance: Adaptability is key to long-term AI success, particularly in dynamic industries like marketing or customer service, where language and user needs evolve quickly. Flexible AI models reduce the need for constant retraining and are more cost-effective over time.
Content Creation & Linguistic Quality
Metrics: Semantic Understanding, Fluency, Coherence, Lexical Diversity.
What It Measures: These metrics assess the quality of AI-generated content, including grammar, fluency, relevance, and coherence.
Significance: High-quality content is essential for applications like report generation, marketing, and automated writing. Ensuring that the AI produces coherent, readable, and grammatically correct content improves user trust and reduces the need for human post-editing.
Knowledge, Fact, and Logic-Based Performance
Metrics: Knowledge Retrieval Score, Truthfulness, Logical Consistency, Reasoning Efficiency.
What It Measures: These metrics focus on the AI’s ability to retrieve accurate knowledge, maintain factual consistency, and apply logical reasoning.
Significance: In fields like healthcare, legal services, and education, factual correctness and logical consistency are critical. These metrics ensure that the AI provides trustworthy information and sound reasoning, reducing the risk of errors that could have significant consequences.
Metric Groups
1. Task-Specific Performance Metrics
Introduction
Task-specific performance metrics are specialized measurements that assess how well a large language model (LLM) performs on narrowly defined tasks. These tasks may range from legal document analysis and technical troubleshooting to specific domain applications such as customer service, healthcare, and finance. Unlike general-purpose metrics, task-specific metrics provide targeted insights into the effectiveness of AI models in practical, real-world applications.
In practice, these metrics are critical for evaluating AI systems that need to meet highly specialized objectives, particularly in industries that demand precision, domain expertise, and contextual understanding. They help businesses ensure that the AI is not only accurate but also relevant to its intended function, improving operational efficiency and decision-making quality.
The following sections will explore each metric in this category, focusing on what it measures, its advantages, and how it is calculated.
1. Task-Specific Performance
What It Measures: This metric evaluates how effectively an LLM performs in a specialized task, such as legal text summarization, technical issue troubleshooting, or financial report generation. The focus is on the model’s ability to understand and execute specific, domain-related tasks.
Key Advantages:
It provides a highly contextualized assessment of performance, ensuring the model can meet domain-specific needs.
Allows businesses to tailor LLMs for particular operational goals, which increases the value of the model in real-world applications.
How It’s Calculated:
Task-specific performance is generally calculated by benchmarking the model against predefined datasets within the domain. For example, in legal document analysis, performance could be measured by comparing AI-generated summaries against expert-written summaries, using metrics like precision and recall. Domain-relevant datasets (such as SQuAD for question-answering or financial datasets for report generation) are essential for this evaluation(Lakera)(ar5iv).
2. Commonsense Reasoning Accuracy
What It Measures: This metric tests the model’s ability to apply commonsense reasoning in decision-making processes, evaluating whether the AI can make logical inferences in situations that require everyday knowledge.
Key Advantages:
Critical for tasks requiring logical conclusions, such as medical diagnostics or legal reasoning, where commonsense assumptions are integral to success.
Enhances user trust by ensuring that the model produces outputs aligned with human logic.
How It’s Calculated:
Commonsense reasoning is often tested using benchmarks like the Winograd Schema Challenge or HellaSwag, which provide scenarios requiring the model to resolve ambiguities based on everyday knowledge. The performance is scored by the percentage of correct inferences made by the model. For example, when presented with two plausible answers, the AI's ability to select the most logical outcome defines its commonsense reasoning performance(Lakera),(ACL Anthology).
3. Domain-Specific Knowledge Integration
What It Measures: This metric evaluates how well an LLM integrates and applies specialized knowledge from a specific field, such as medicine, finance, or law, into its generated outputs.
Key Advantages:
Ensures the model is not only proficient in general language tasks but also in applying industry-specific information accurately.
Enhances the utility of LLMs in specialized professions that rely on in-depth knowledge.
How It’s Calculated:
The model’s domain knowledge is typically tested using tasks that require specialized vocabulary and procedures. For example, in medicine, the model could be tested on its ability to generate correct responses based on clinical case descriptions using datasets like MedQA or MIMIC-III. Performance is scored by comparing the AI-generated results with expert benchmarks, evaluating accuracy, precision, and recall based on specific, industry-focused criteria(ar5iv)(ar5iv).
4. Cross-Task Generalization
What It Measures: Cross-task generalization evaluates how well the model performs across a wide variety of tasks, not just the task it was originally trained on. It assesses the model's ability to transfer knowledge from one domain to another.
Key Advantages:
Provides insights into the model's versatility and ability to apply learned information across different tasks.
Useful for organizations that require multi-functional AI systems capable of handling a broad range of activities.
How It’s Calculated:
Cross-task generalization is tested using a diverse set of benchmarks, such as the GLUE or SuperGLUE datasets, which include various tasks such as sentiment analysis, question-answering, and textual entailment. The model’s ability to perform consistently well across these different tasks reflects its generalization capability. Performance is typically measured using a combination of accuracy, F1 scores, and area under the curve (AUC) metrics across the different tasks(Lakera)(ACL Anthology).
5. User Personalization Precision
What It Measures: This metric measures the model's ability to personalize outputs based on individual user preferences or past interactions, such as recommending personalized content in an e-commerce setting.
Key Advantages:
Enhances user satisfaction by generating outputs that are highly relevant and tailored to specific users.
Critical for recommendation systems, customer support, and personalized marketing applications where user context matters.
How It’s Calculated:
Personalization precision is often measured by the relevance of outputs in comparison to user profiles or preferences. This is done through collaborative filtering, which looks at user behavior and past interactions to generate recommendations. A common metric used is the precision at k (P@k), which evaluates how often the top k recommendations or responses are relevant to the user(ar5iv)(Lakera).
6. Zero-Shot Learning Efficiency
What It Measures: This metric tests how well the model can perform a task without having been specifically trained on that task or given labeled examples beforehand.
Key Advantages:
Enables more flexible deployment of models in scenarios where task-specific data may not be available.
Reduces the need for costly and time-consuming data labeling processes.
How It’s Calculated:
Zero-shot learning efficiency is evaluated by testing the model on tasks that it has never seen before, using benchmarks like TREC for information retrieval or WinoGrande for commonsense reasoning. The model's performance is assessed by its ability to make predictions based solely on general language understanding, using accuracy and F1 scores(ar5iv)(ar5iv).
2. Human Interaction & Communication Metrics
Introduction
Human interaction and communication metrics evaluate how effectively large language models (LLMs) engage with users in real-time interactions. These metrics are particularly important for tasks where the model interacts with humans, such as virtual assistants, chatbots, customer service systems, and healthcare applications. These metrics not only assess technical accuracy but also evaluate the nuances of communication, such as empathy, context awareness, and the ability to maintain coherent and meaningful conversations.
In practical applications, these metrics are critical because human users expect AI to generate responses that are not only correct but also contextually appropriate, emotionally engaging, and tailored to individual needs. Effective human-AI interaction can improve user satisfaction, trust, and even operational outcomes such as customer retention or patient compliance in healthcare.
Below, each metric is discussed in detail, including what it measures, its key advantages, and how it is calculated in real-world scenarios.
1. Compassion Response Score
What It Measures: This metric evaluates the ability of an LLM to generate empathetic and compassionate responses, particularly in sensitive interactions such as healthcare or customer service.
Key Advantages:
Enhances user satisfaction by mimicking compassionate human communication.
Can improve patient engagement and adherence to treatment in healthcare settings, where empathy plays a significant role.
How It’s Calculated:
The Compassion Response Score is often assessed using user feedback and qualitative human judgment. In healthcare, for example, AI-generated messages are compared to human-written responses for their emotional tone and compassion. Additionally, sentiment analysis tools can quantify the emotional content of AI responses. For real-world implementation, human evaluators might score interactions on empathy scales to assess how effectively the model mimics human-like compassion(Psychology Today)(Lakera).
2. Interactive Dialogue Quality
What It Measures: This metric assesses the model's ability to maintain coherent, engaging, and meaningful dialogues over multiple turns. It focuses on how well the model responds to context and keeps the conversation relevant.
Key Advantages:
Ensures that the AI can handle complex interactions that span several turns, a critical capability for virtual assistants and chatbots.
Reduces user frustration by keeping interactions fluid and minimizing abrupt or nonsensical responses.
How It’s Calculated:
Dialogue quality is often measured using metrics such as Dialog Success Rate (DSR), which evaluates whether the AI successfully achieves the intended goal of the interaction (e.g., booking a service, answering a query). Other methods include human-in-the-loop evaluations where conversations are scored for coherence, relevance, and user satisfaction. BLEU and ROUGE metrics, traditionally used in machine translation, can also be adapted to measure linguistic similarity and relevance across dialogue exchanges(Lakera)(ar5iv).
3. Sentiment Alignment
What It Measures: This metric evaluates how well the emotional tone of the AI’s response aligns with the user’s emotional state or the intended sentiment of the conversation. For example, ensuring that the AI responds with empathy to a frustrated user.
Key Advantages:
Critical for customer service applications, where misaligned sentiment (e.g., responding coldly to an angry customer) could lead to dissatisfaction.
Enhances user experience by making interactions feel more natural and human.
How It’s Calculated:
Sentiment alignment is often measured using sentiment analysis models that score both the user’s input and the AI’s output on an emotional spectrum (positive, neutral, negative). The alignment is then quantified by comparing how closely the sentiment of the model’s response matches the expected emotional tone. Feedback loops using user ratings or satisfaction surveys can also measure alignment by assessing whether users feel the AI understands and responds appropriately to their emotional state(Psychology Today)(Knowledge at Wharton).
4. Human-Like Consistency Index
What It Measures: This metric evaluates the model's ability to generate responses that are consistent with human conversational patterns over long exchanges. It focuses on maintaining logical coherence, avoiding contradictions, and sounding natural throughout the conversation.
Key Advantages:
Critical for applications where the AI is expected to handle extended interactions without causing confusion or generating contradictory statements.
Enhances user trust by ensuring the AI behaves in a consistent and predictable manner.
How It’s Calculated:
Human-like consistency is usually measured through coherence scoring methods. This involves analyzing multiple turns of conversation for logical flow, consistency in tone, and adherence to previously given information. Tools like Linguistic Annotation and Feedback Tools (LAF) can also be used to detect contradictions or changes in narrative tone across conversation turns(Lakera)(ar5iv).
5. Context Awareness Score
What It Measures: This metric evaluates how well the model retains and utilizes contextual information throughout the interaction, ensuring that it doesn’t lose track of important details provided by the user earlier in the conversation.
Key Advantages:
Ensures fluidity in long conversations, where the AI needs to remember and refer back to previous details.
Critical for customer service or virtual assistants that handle multi-step processes or follow-up interactions.
How It’s Calculated:
Context awareness is assessed using tasks that involve multi-turn conversations where context retention is key. The model's ability to refer back to earlier parts of the conversation is evaluated, often using dialogue history tracking techniques. For instance, the model’s outputs can be analyzed to see if it accurately remembers details like user preferences, prior questions, or task-specific information(Lakera)(ACL Anthology).
3. Security, Ethical, and Compliance Metrics
Introduction
Security, ethical, and compliance metrics are crucial for evaluating the safety and trustworthiness of large language models (LLMs) in real-world applications. These metrics focus on ensuring that AI models operate within the bounds of ethical standards, resist manipulation, and comply with regulatory guidelines. They are particularly important in industries like finance, healthcare, and law, where the repercussions of biased or harmful AI outputs can be severe.
By evaluating AI through this lens, organizations can mitigate risks such as biased decision-making, unethical outputs, and security vulnerabilities. These metrics ensure that AI models not only deliver accurate results but also behave responsibly, aligning with industry regulations and ethical standards.
Below is a detailed examination of each metric in this category, including what it measures, its advantages, and how it is calculated.
1. Bias Detection Index
What It Measures: This metric assesses how well the model can detect and mitigate bias in its outputs, particularly biases related to race, gender, age, and other sensitive categories.
Key Advantages:
Ensures fairness and reduces the risk of discrimination in automated decision-making processes.
Vital for maintaining ethical standards in areas such as hiring, lending, and law enforcement.
How It’s Calculated:
Bias detection is typically evaluated by inputting queries designed to probe for biased behavior. Outputs are then analyzed using fairness metrics such as Equal Opportunity Difference (EOD) or Disparate Impact Ratio (DIR). Statistical methods like t-tests or chi-square tests can be applied to determine whether the model's outputs show significant bias when compared across different demographic groups(ar5iv)(ACL Anthology).
2. Ethical Compliance Rating
What It Measures: This metric evaluates whether the AI’s outputs comply with ethical guidelines, especially in regulated industries. It ensures the model behaves within the ethical boundaries set by governing bodies and industry standards, such as avoiding the generation of harmful, offensive, or illegal content.
Key Advantages:
Critical for deployment in industries where regulatory compliance is non-negotiable, such as healthcare, finance, or law.
Prevents AI from engaging in unethical behavior, such as producing biased, harmful, or deceptive outputs.
How It’s Calculated:
Ethical compliance is often measured through manual audits and predefined benchmarks like ISO/IEC 23053 for AI ethics. Specific tests include querying the model with ethically sensitive inputs to check for adherence to guidelines, with violations flagged and scored according to predefined thresholds. Feedback loops involving expert human reviewers may also be used to refine the model’s outputs(Lakera)(ar5iv).
3. Adversarial Input Handling
What It Measures: This metric evaluates the model's robustness against adversarial attacks—inputs specifically designed to confuse or deceive the AI, potentially leading it to produce harmful or erroneous outputs.
Key Advantages:
Enhances the security of AI systems by ensuring that they can resist manipulation by malicious actors.
Essential for AI applications in security-sensitive industries like cybersecurity and fraud detection.
How It’s Calculated:
Adversarial robustness is tested by subjecting the model to adversarial examples, such as inputs with slight alterations designed to mislead the AI (e.g., word swaps or perturbations). Attack simulations using tools like FGSM (Fast Gradient Sign Method) or PGD (Projected Gradient Descent) can assess how resilient the model is to these manipulations. Success is measured by the AI's accuracy under attack compared to baseline performance(ar5iv)(ACL Anthology).
4. Toxicity Avoidance Score
What It Measures: This metric evaluates the AI's ability to avoid generating harmful, toxic, or offensive content, which could include hate speech, profanity, or defamatory statements.
Key Advantages:
Reduces the risk of reputational damage and legal liability from AI outputs that may be deemed offensive or harmful.
Critical for customer-facing applications where the AI must maintain a positive and respectful tone, such as social media moderation or virtual assistants.
How It’s Calculated:
Toxicity avoidance is measured using tools like Perspective API, which scores outputs on a scale of toxicity. The model's outputs are tested against a range of potentially toxic prompts, and its ability to avoid generating offensive content is scored based on predefined toxicity thresholds. Additionally, human evaluators may review outputs flagged as borderline toxic for further analysis(ar5iv)(Lakera).
5. Truthfulness and Hallucination Detection
What It Measures: This metric assesses the model’s ability to generate factual and truthful information, avoiding "hallucinations"—instances where the AI fabricates facts or provides incorrect information.
Key Advantages:
Essential for applications where factual accuracy is paramount, such as in research, education, or journalism.
Reduces risks associated with misinformation, which can have legal and ethical consequences.
How It’s Calculated:
Truthfulness is measured by comparing the AI's outputs to verified databases or authoritative sources. Fact-checking tools can automate parts of this process by cross-referencing the generated content with reliable datasets. Metrics like Precision@k or Recall@k can quantify how often the AI's outputs align with factual information. Human reviewers may also be employed to assess the accuracy of more nuanced outputs(ar5iv)(ar5iv).
4. Operational Performance Metrics
Introduction
Operational performance metrics measure how well large language models (LLMs) function in real-world environments, particularly focusing on speed, stability, robustness, and scalability. These metrics are critical for ensuring that the AI performs reliably under various operational conditions, such as high user traffic, live environments, and continuous model updates. In practical applications, especially in business settings, these metrics help organizations ensure that their AI systems are efficient and robust enough to be deployed at scale without sacrificing user experience or accuracy.
These metrics are especially important for mission-critical applications, such as customer service platforms, where delays or inconsistencies can impact the end-user experience. Understanding these metrics enables businesses to monitor and optimize their AI systems for sustained and predictable performance.
Below, each metric is described in detail, explaining what it measures, its key advantages, and how it is calculated.
1. Inference Latency
What It Measures: Inference latency refers to the time it takes for the model to generate an output after receiving an input query. This is crucial for real-time applications where response speed directly affects user experience, such as chatbots, virtual assistants, and customer service platforms.
Key Advantages:
Enhances user experience by minimizing wait times for responses in real-time applications.
Critical for applications that rely on rapid interactions, such as customer service or automated trading systems.
How It’s Calculated:
Inference latency is calculated by measuring the time elapsed from when the input is received to when the output is delivered. The latency is typically measured in milliseconds (ms). For large-scale AI models, infrastructure optimizations such as batch processing or model distillation can reduce latency without compromising model quality(Lakera)(ar5iv).
2. Real-World Deployment Resilience
What It Measures: This metric assesses the model's performance stability in live, production environments over extended periods. It evaluates how well the model handles real-world conditions such as fluctuating user demand, network issues, and integration with other systems.
Key Advantages:
Ensures the AI system remains reliable and efficient when deployed at scale in unpredictable environments.
Reduces the risk of system failures or performance degradation in live applications, such as customer service, e-commerce, or financial systems.
How It’s Calculated:
Real-world deployment resilience is measured through stress testing, where the model is subjected to real-time usage with varying loads. Performance metrics like uptime, error rates, and throughput are monitored to ensure the model performs consistently under different conditions. Monitoring tools and dashboard analytics are often used to track these metrics in real-time(Knowledge at Wharton)(Lakera).
3. Stability Across Versions
What It Measures: This metric evaluates the model’s ability to maintain performance consistency across different versions and updates. It ensures that improvements in one area do not negatively affect the model's performance in others, such as accuracy or speed.
Key Advantages:
Maintains user trust by ensuring predictable and consistent performance despite updates.
Reduces risks associated with new releases that might introduce errors or degrade performance in existing functionalities.
How It’s Calculated:
Stability across versions is often measured by comparing key performance metrics (e.g., accuracy, latency, and robustness) across different versions of the model. Regression testing and A/B testing are used to evaluate whether the newer versions of the model introduce any regressions in performance. Monitoring tools track these metrics to detect and correct any potential issues early in the release cycle(ar5iv)(Lakera).
4. Explainability and Interpretability
What It Measures: Explainability and interpretability measure how well the inner workings of the AI model can be understood and explained, particularly to non-technical stakeholders. This is especially important in regulated industries, where transparency is required to justify decisions made by the model.
Key Advantages:
Increases trust and accountability, especially in high-stakes applications like finance, healthcare, or law.
Allows stakeholders, such as auditors or regulators, to understand how and why the model arrived at specific decisions.
How It’s Calculated:
Explainability is measured by tools like SHAP (Shapley Additive Explanations) and LIME (Local Interpretable Model-Agnostic Explanations), which break down the model's decision-making process. These tools allow users to visualize which input features contributed the most to the model’s outputs. These explanations are then compared to human reasoning to ensure alignment(
5. Business & Economic Impact Metrics
Introduction
Business and economic impact metrics are designed to assess the broader effects of deploying large language models (LLMs) within a business context. These metrics go beyond measuring accuracy or technical performance, focusing instead on how LLMs contribute to business outcomes, such as productivity, cost reduction, and overall economic efficiency. For enterprises, understanding these metrics is crucial to evaluating the return on investment (ROI) from AI technologies, particularly when deploying LLMs in mission-critical or customer-facing environments.
These metrics play a pivotal role in helping businesses quantify the tangible and intangible benefits of AI adoption, ensuring that models not only function well but also align with corporate objectives like profitability, customer satisfaction, and operational efficiency.
In the sections below, each metric in this category is explained, including what it measures, its key advantages, and how it is calculated in practice.
1. Economic Impact Simulation
What It Measures: This metric simulates the potential economic benefits or costs of deploying an LLM in various business applications. It assesses factors like productivity gains, cost savings, and revenue growth as a result of the AI model's implementation.
Key Advantages:
Provides a clear estimation of how AI adoption will impact a company’s bottom line, helping to justify investment in LLM technologies.
Useful for businesses looking to scale AI applications across different departments, such as customer service, marketing, or research and development.
How It’s Calculated:
Economic impact is calculated by simulating scenarios where the AI is deployed, using business metrics such as cost-per-interaction, customer churn rate, and employee efficiency as baselines. Companies often employ ROI calculators or Total Cost of Ownership (TCO) models to estimate the financial benefits over time. For example, businesses might measure how much AI reduces human labor costs by automating customer service queries and calculate savings over months or years(Knowledge at Wharton)(Lakera).
2. Business Relevance Score
What It Measures: This metric evaluates how well the AI model aligns with the specific objectives of the business, such as improving customer satisfaction, reducing response times, or increasing content creation efficiency. It gauges the practical relevance of the model to the company's operational goals.
Key Advantages:
Ensures that AI models are not only functional but also delivering value in key business areas.
Helps prioritize AI models that best support business goals like enhancing customer experience or optimizing internal processes.
How It’s Calculated:
Business relevance is measured by mapping AI outcomes to specific key performance indicators (KPIs) that the organization tracks, such as Net Promoter Score (NPS), customer retention rates, or cost-per-acquisition. The model’s impact is scored based on how effectively it helps achieve these KPIs over time. This can involve tracking metrics before and after AI implementation to assess improvements(Lakera)(ACL Anthology).
3. Cost-Efficiency Ratio
What It Measures: This metric calculates the ratio of the financial investment required to develop and maintain the LLM versus the cost savings or revenue gains it generates. It provides an overall picture of the model’s economic viability.
Key Advantages:
Allows businesses to understand if their AI investment is delivering sufficient financial returns.
Helps compare different AI models or systems to choose the most cost-effective solution for scaling across the organization.
How It’s Calculated:
The cost-efficiency ratio is calculated by dividing the total operating costs (including development, training, and maintenance) by the financial benefits the model generates (e.g., reduced labor costs, increased sales, or improved operational efficiency). A cost-efficiency ratio below 1 indicates that the AI is yielding more value than it costs to operate(Knowledge at Wharton)(ar5iv).
4. Productivity Enhancement Index
What It Measures: This metric assesses how much the AI model improves the productivity of human workers by automating repetitive tasks, enhancing decision-making, or supporting collaboration.
Key Advantages:
Demonstrates the AI’s role in optimizing workflows and reducing the time it takes to complete certain tasks.
Encourages businesses to use AI to complement human workers rather than replace them, enhancing overall operational efficiency.
How It’s Calculated:
Productivity is often measured using output per employee before and after AI adoption. This might include metrics like the number of customer queries resolved per hour, time saved on report generation, or the reduction in errors made by human workers when using AI-assisted tools. Productivity increases are then translated into financial savings or output improvements, which are aggregated into an overall index score()(
).
5. ROI (Return on Investment) for AI Deployment
What It Measures: This metric calculates the overall return on investment from deploying the LLM by comparing the net financial gains to the costs of development, training, and maintenance of the AI system.
Key Advantages:
Provides a concrete measure of how profitable the AI deployment has been, helping justify further investment in AI technologies.
Useful for CFOs and executives who need a clear financial picture of AI’s impact on the organization.
How It’s Calculated:
ROI is calculated using the formula: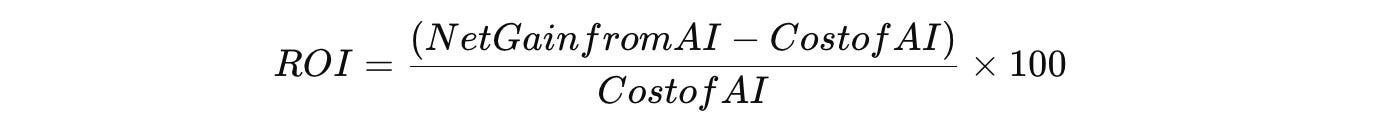
where Net Gain from AI includes benefits such as increased revenue, reduced costs, or efficiency gains. Companies often use financial data collected over months or quarters to calculate a more accurate ROI for their AI projects(
6. Adaptability & Flexibility Metrics
Introduction
Adaptability and flexibility metrics assess how well large language models (LLMs) can adjust to changes in language, environments, and user input. These metrics are crucial for evaluating the model’s ability to function effectively in diverse and evolving scenarios. For businesses, it’s important that LLMs can handle variations in prompts, changing user demands, or new types of data without requiring extensive retraining.
By ensuring that models are adaptable and flexible, organizations can deploy AI solutions that remain effective in dynamic environments, where user expectations, language patterns, and business needs can shift rapidly. These metrics are particularly important in applications like customer service, content generation, and real-time interaction platforms, where the ability to respond to evolving input is critical.
The following sections break down each metric in this group, discussing what it measures, its key advantages, and how it is calculated.
1. Dynamic Language Adaptation
What It Measures: This metric evaluates the model's ability to stay up-to-date with changing language trends, such as new slang, terminologies, or cultural references. It ensures that the model remains relevant and effective in real-world language usage that evolves over time.
Key Advantages:
Keeps the AI relevant in fast-moving industries like marketing, social media, or customer service, where language evolves quickly.
Reduces the need for frequent retraining as the model can adapt to new linguistic trends on its own.
How It’s Calculated:
Dynamic language adaptation is often assessed through continuous monitoring of the model’s outputs against current language trends. Online learning techniques can help keep the model updated by incrementally training it with new data. The model’s ability to correctly understand and incorporate recent trends can be measured through evaluation on dynamic datasets or user feedback that focuses on its use of contemporary language(Lakera)(ar5iv).
2. Prompt Engineering Robustness
What It Measures: This metric assesses how well the model handles variations in prompt phrasing and structure. It tests the model’s ability to interpret and respond appropriately to different types of user inputs, even if they are not phrased in the way the model was initially trained to understand.
Key Advantages:
Enhances the model's usability by ensuring that it can handle diverse prompts, reducing the need for precise input from users.
Improves flexibility in real-world scenarios where user input may be unclear, incomplete, or varied.
How It’s Calculated:
Prompt engineering robustness is measured by providing the model with a variety of prompts that convey the same intention but are phrased differently. The performance is assessed by how well the model maintains consistency in its responses despite variations. This can be calculated using semantic similarity scores between the intended output and the model's actual output across different prompt formats(ar5iv)(ar5iv).
3. Cross-Language Transferability
What It Measures: This metric evaluates the model’s ability to generalize its knowledge and outputs across different languages. It assesses how well a model trained predominantly in one language can perform in others, especially when handling multilingual content or user queries.
Key Advantages:
Critical for global businesses or applications where multilingual support is necessary, such as customer service or content generation in different markets.
Reduces the need for training separate models for each language, improving efficiency in AI deployments across diverse language environments.
How It’s Calculated:
Cross-language transferability is often measured using multilingual benchmarks like XGLUE or XTREME, which test the model’s performance across different languages. The model's ability to generate accurate outputs or translations is scored based on language-specific metrics such as BLEU for machine translation or Word Error Rate (WER) for speech recognition. It is particularly useful in evaluating how well the model adapts to languages it was not primarily trained on(Lakera)(ACL Anthology).
4. Task Generalization across Domains
What It Measures: This metric evaluates the model’s ability to transfer knowledge from one task or domain to another. It assesses how well the model can apply its learned knowledge in new, unfamiliar contexts without requiring additional training for every task.
Key Advantages:
Increases the model’s flexibility, allowing businesses to deploy it across a wide range of tasks without needing to build multiple specialized models.
Reduces the costs associated with retraining models for each new task, improving the scalability of AI systems in enterprise environments.
How It’s Calculated:
Task generalization is typically measured by testing the model on unseen tasks or datasets that are outside its initial training domain. Performance is evaluated using accuracy or F1 scores on these new tasks compared to its performance in the original task domain. Transfer learning techniques are often applied, and the success of task generalization can be quantified by how much training data the model requires to adapt to the new domain(ar5iv)(Lakera).
5. Robustness to Noisy Input
What It Measures: This metric evaluates the model's ability to handle noisy, incomplete, or inaccurate input data, such as misspellings, grammatical errors, or incomplete sentences. It tests how well the model can still generate useful outputs when faced with imperfect data.
Key Advantages:
Critical for real-world applications where users may not always provide clean or well-formed input, especially in casual conversations or customer service interactions.
Reduces the need for input preprocessing, improving the model’s robustness and making it more user-friendly in noisy environments.
How It’s Calculated:
Robustness to noisy input is measured by deliberately introducing noise—such as typos, grammatical errors, or missing context—into test datasets and analyzing how well the model still generates coherent and correct outputs. Performance is compared with baseline outputs using Levenshtein distance or WER to quantify how much deviation the noise causes in the final result(Lakera)(ar5iv).
7. Content Creation & Linguistic Metrics
Introduction
Content creation and linguistic metrics are used to evaluate the quality, fluency, and coherence of text or other outputs generated by large language models (LLMs). These metrics are especially important for applications such as machine translation, content generation, summarization, and report writing. The goal of these metrics is to ensure that the AI produces text that is not only factually correct but also linguistically appropriate and coherent, with attention to fluency, grammar, and overall structure.
In practice, these metrics are vital for companies that rely on AI for generating customer-facing content, creative writing, or automated reporting. They help businesses ensure that the language produced by the model meets the required standards of quality, whether for internal documentation or external marketing purposes.
Below, each metric in this category is described, including what it measures, its key advantages, and how it is calculated.
1. Semantic Understanding Index
What It Measures: This metric evaluates how well the AI understands the semantic meaning of complex sentences and whether it captures nuances beyond surface-level word matching. It focuses on whether the model can generate text that accurately conveys the intended meaning or idea.
Key Advantages:
Essential for tasks such as summarization and question answering, where the AI needs to understand and convey complex ideas accurately.
Helps ensure that generated content is logically coherent and contextually appropriate, reducing the risk of misinterpretation or ambiguity.
How It’s Calculated:
Semantic understanding is typically evaluated using benchmarks such as GLUE or SuperGLUE, which test various aspects of natural language understanding, including sentence similarity, inference, and contextual relevance. BERTScore and Cosine Similarity are commonly used to calculate the similarity between the generated and reference texts based on their embeddings, capturing the semantic overlap(Lakera)(ar5iv).
2. Content Fluency Index
What It Measures: This metric assesses the grammatical correctness and overall fluency of the AI’s outputs. It measures whether the text flows naturally, reads smoothly, and adheres to standard language rules.
Key Advantages:
Critical for applications like marketing content, customer communication, or editorial work, where readability and grammatical accuracy are paramount.
Helps maintain professionalism and clarity in AI-generated content, reducing the need for human post-editing.
How It’s Calculated:
Content fluency can be measured using automated tools such as Grammarly or LanguageTool, which check for grammatical errors, punctuation, and overall readability. Fluency scores are derived from these tools, with additional assessments such as perplexity (lower perplexity indicates better fluency) and Gunning Fog Index, which estimates the readability of the text based on sentence length and word complexity(Lakera)(ACL Anthology).
3. Long-Term Relevance Score
What It Measures: This metric evaluates whether the content generated by the AI remains relevant and accurate over time. It’s particularly useful in applications where the AI produces evergreen content, such as product descriptions or informational articles, which need to remain useful for an extended period.
Key Advantages:
Ensures that the content generated by AI does not become outdated quickly, reducing the need for frequent revisions.
Particularly important in areas such as e-commerce, where product descriptions or marketing materials may be reused over time.
How It’s Calculated:
Long-term relevance is often measured through content decay analysis, where the relevance and accuracy of the content are tracked over time using user engagement metrics, such as click-through rates or customer feedback. AI-generated content can also be periodically compared against updated datasets to check for factual accuracy and continued relevance(Knowledge at Wharton)(Lakera).
4. Lexical Diversity Index
What It Measures: This metric evaluates the richness and variety of the vocabulary used in AI-generated text. It assesses whether the language model avoids repetition and uses a broad range of words to convey ideas effectively.
Key Advantages:
Useful in creative writing, marketing, or any context where engaging and varied language is needed to maintain reader interest.
Helps improve the perceived quality of the content by making it more dynamic and less monotonous.
How It’s Calculated:
Lexical diversity can be measured using the Type-Token Ratio (TTR), which compares the number of unique words (types) to the total number of words (tokens) in a text. Higher TTR values indicate greater lexical diversity. MTLD (Measure of Textual Lexical Diversity) and VOCD are more advanced measures that adjust for text length and provide a more nuanced view of vocabulary use(ar5iv)(ACL Anthology).
5. Coherence Score
What It Measures: This metric assesses how logically and consistently the AI’s outputs are structured. It checks whether the content flows smoothly from one idea to the next, without contradictions or abrupt transitions.
Key Advantages:
Important for generating long-form content such as reports, articles, or narratives, where maintaining logical flow is critical for reader comprehension.
Reduces the risk of disjointed or confusing outputs, which can degrade the quality and usability of the content.
How It’s Calculated:
Coherence is often measured through manual reviews or automated tools that track the logical progression of ideas in the text. For instance, discourse parsing techniques can be used to map how sentences and paragraphs relate to one another. Entity grid models can also be applied to quantify coherence by analyzing the distribution of entities (people, objects, concepts) across the text(ar5iv)(ar5iv).
8. Knowledge, Fact, and Logic-Based Metrics
Introduction
Knowledge, fact, and logic-based metrics are designed to evaluate the depth of a model’s factual accuracy, logical consistency, and knowledge retrieval capabilities. These metrics are particularly important for applications where the AI must generate factually correct and logically sound information, such as in research, legal settings, healthcare, or educational content generation. As LLMs are increasingly used to generate large volumes of information, these metrics help assess whether the AI can reliably distinguish between correct and incorrect data and apply reasoning to support its outputs.
These metrics are essential for ensuring that AI systems are trustworthy and that their outputs can be confidently used in decision-making processes. Below, each metric in this category is detailed, including what it measures, its advantages, and how it is calculated.
1. Knowledge Retrieval Score
What It Measures: This metric evaluates the model's ability to retrieve and apply factual information from its training data when responding to queries. It checks whether the AI can accurately reference and present domain-specific or general knowledge.
Key Advantages:
Essential for applications like customer support, research, and educational content, where factual accuracy is paramount.
Helps ensure the AI can provide detailed, contextually appropriate responses across different subject areas.
How It’s Calculated:
Knowledge retrieval is measured by testing the model against large, factual datasets such as Wikipedia or domain-specific corpora (e.g., medical texts, legal documents). The AI's responses are compared to known correct answers, and accuracy is assessed using metrics like precision, recall, and F1 score. Human evaluators can also be involved in verifying the factual correctness of complex or nuanced outputs(ar5iv)(ACL Anthology).
2. Truthfulness and Hallucination Detection
What It Measures: This metric assesses the AI’s ability to avoid generating false or fabricated information, known as “hallucinations.” It evaluates the truthfulness of the model’s outputs, ensuring the information aligns with verified knowledge sources.
Key Advantages:
Critical in fields like journalism, research, and healthcare, where the generation of false information can lead to significant harm.
Increases trust in AI-generated content by reducing the risk of misinformation.
How It’s Calculated:
Truthfulness is typically measured by comparing the model’s outputs against a ground-truth database or trusted knowledge sources. Human reviewers may also be employed to cross-check information, especially in complex domains. Models like OpenAI’s GPT-3 or ChatGPT can be tested on datasets such as TruthfulQA, which assesses the model’s ability to generate honest answers. Hallucination detection tools use log-likelihood scoring to identify and flag content that seems overly speculative or non-factual(ar5iv)(Lakera).
3. Logical Consistency Score
What It Measures: This metric evaluates the model’s ability to generate logically coherent and consistent information, ensuring that its outputs do not contain contradictions or faulty reasoning.
Key Advantages:
Important for decision-making systems in legal, financial, or strategic applications where consistency and logic are crucial.
Reduces the risk of contradictory or incoherent outputs that can confuse users or undermine trust in the system.
How It’s Calculated:
Logical consistency is often measured through manual evaluation or automated tools that analyze outputs for contradictions or gaps in reasoning. For example, in the legal domain, the AI may be tested with case studies requiring the application of laws or principles consistently across scenarios. Logic-based reasoning tests such as Winograd Schema Challenge or logical entailment tasks can be used to assess the model's ability to apply consistent reasoning across different questions(ar5iv)(ACL Anthology).
4. Fact-Checking Efficiency
What It Measures: This metric assesses the speed and accuracy with which the model can cross-reference facts or data points during text generation or knowledge retrieval tasks.
Key Advantages:
Improves the model's utility in fast-paced environments such as real-time information systems or content generation platforms.
Reduces the time human users need to spend verifying AI outputs, improving workflow efficiency.
How It’s Calculated:
Fact-checking efficiency can be measured by evaluating how quickly the model responds with factually accurate information when compared to a human performing the same task. Automated fact-checking systems like ClaimBuster or FactBench are often used to test the AI’s ability to identify and verify claims in real-time. Performance is scored based on the speed and accuracy of the fact-checking process(Lakera)(ar5iv).
5. Reasoning and Inference Score
What It Measures: This metric evaluates how well the model can apply reasoning and inference to derive conclusions based on given data. It is crucial in domains requiring complex decision-making or predictive capabilities, such as legal analysis or scientific research.
Key Advantages:
Enhances the model’s ability to perform in advanced problem-solving tasks where logical inference is required.
Critical for fields such as diagnostics, where reasoning-based conclusions can inform critical decisions.
How It’s Calculated:
Reasoning is measured using tasks that require logical deduction or predictive inference, such as natural language inference (NLI) tasks or reasoning challenges like RTE (Recognizing Textual Entailment). These tasks assess the model’s ability to draw valid conclusions from premises. Confusion matrices or F1 scores are often used to evaluate how accurately the model applies reasoning to reach correct conclusions(ar5iv)(Lakera).
 | A guest post by
|